
EmoDiff: Intensity controllable emotional text-to-speech with soft-label guidance
Published in IEEE ICASSP, 2023
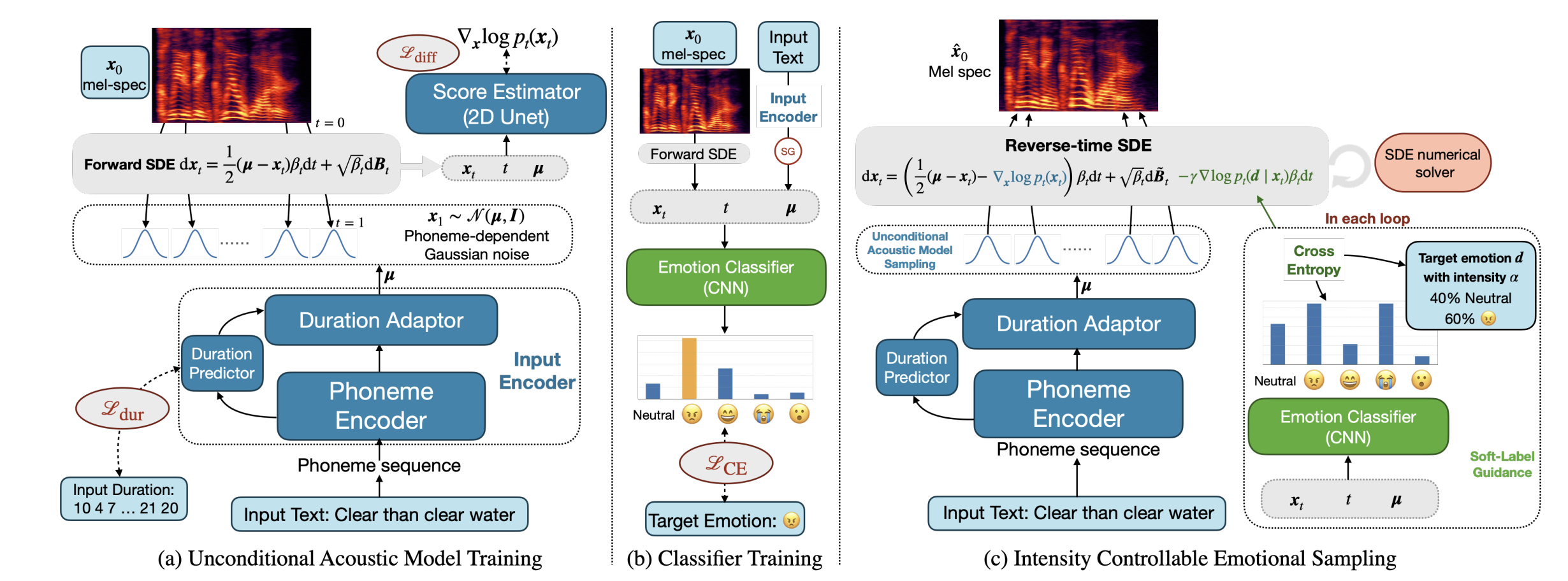
Although current neural text-to-speech (TTS) models are able to generate high-quality speech, intensity controllable emotional TTS is still a challenging task. Most existing methods need external optimizations for intensity calculation, leading to suboptimal results or degraded quality. In this paper, we propose EmoDiff, a diffusion-based TTS model where emotion intensity can be manipulated by a proposed soft-label guidance technique derived from classifier guidance. Specifically, instead of being guided with a one-hot vector for the specified emotion, EmoDiff is guided with a soft label where the value of the specified emotion and Neutral is set to α and 1 − α respectively. The α here represents the emotion intensity and can be chosen from 0 to 1. Our experiments show that EmoDiff can precisely control the emotion intensity while maintaining high voice quality. Moreover, diverse speech with specified emotion …
Recommended citation: Yiwei Guo, Chenpeng Du, Xie Chen, Kai Yu. (2023). "EmoDiff: Intensity controllable emotional text-to-speech with soft-label guidance." In Proc. IEEE ICASSP, 2023.