
Datasets
StoryTTS: A Highly Expressive Text-to-Speech Dataset with Rich Textual Expressiveness Annotations
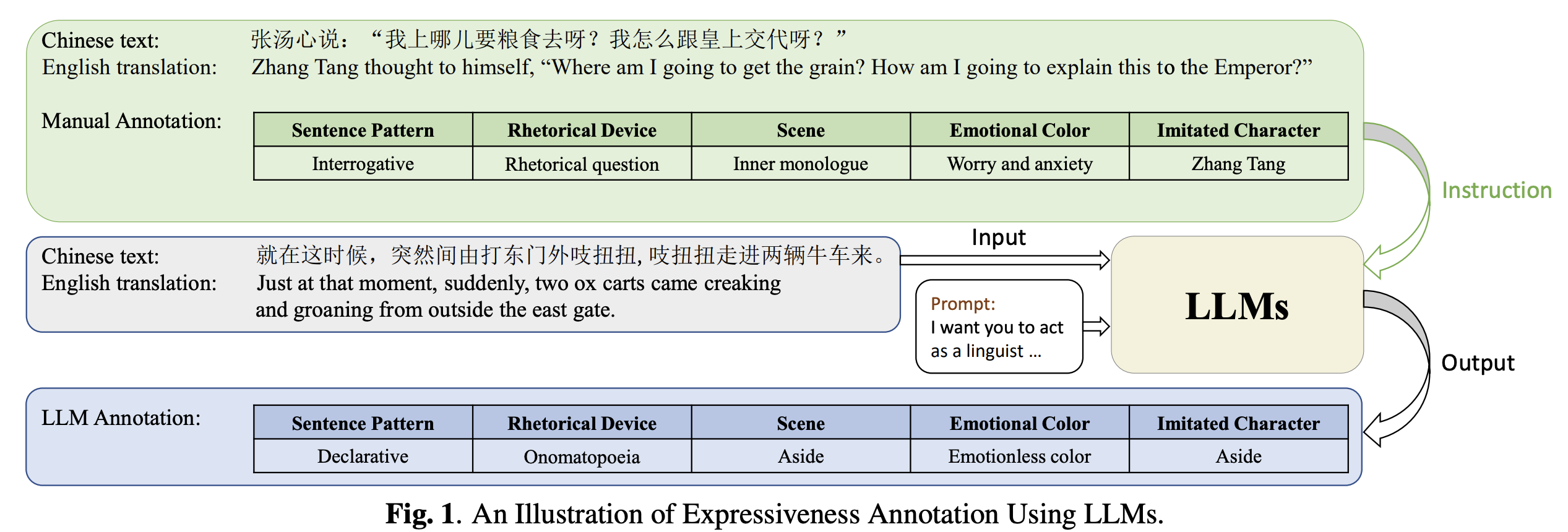
StoryTTS is a highly expressive text-to-speech dataset that contains rich expressiveness both in acoustic and textual perspectives, from the recording of a Mandarin storytelling show (评书), which is delivered by a female artist, Lian Liru (连丽如). It contains 61 hours of consecutive and highly prosodic speech equipped with accurate text transcriptions and rich textual expressiveness annotations.